声纹识别和我们生活中常听到的语音识别不同,虽然都是对声音进行检测识别,但是语音识别检测的是我们讲了什么,而声纹识别则是检测讲话的人是谁。因此声纹识别也叫说话人识别,一般被用来解决身份确认和识别的问题。
那么,声纹识别是怎么样的一个过程呢?下面我们简单介绍一下这个过程:首先,要进行声纹识别,肯定要先有语音材料,我们需要事先上传语音进行身份注册。通俗的讲就是告诉系统,这个语音是谁的?后面我们再上传语音询问系统这个语音的主人是谁时,系统就会将测试语音和所知道的语音进行比对,然后输出这个声音的主人名字。那么问题又来了,系统是如何将测试语音与已知语音进行比对的呢?我们知道,每个人讲话的声音都有各自的特点,这是由声腔差异和发声方式不同所导致的。因此,虽然两个不同的人讲同一句话,但是他们所发出的声音频率、振幅等等肯定是不同的。通过可视化技术,我们可以看到语音的波形以及频谱等图像。于是,这些不同的地方就会成为我们每个人的语音特征。声纹识别系统会先分析这些语音的特征,提取它们的特征值,这样子,一条语音就变成了很多个13维的特征值数组。
接下来,如何通过特征值比对找出与测试语音最相似的语音就是重点所在了。同学们还记得前面我们介绍过的KNN(分类)算法吗?我们把每个特征值数组当作一个点,KNN算法所做的就是求出点与点之前的距离,距离越近说明两个语音之间的相似度越高。那么根据这个方法我们可以对他们的距离进行计算,以找出两个最相似的语音。如下图中所展示的一样,点与点之间的距离就表示了他们的相似度。
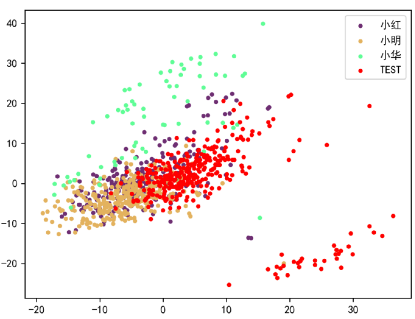
图1 语音特征点图
通过这种方式,我们就能得到与测试语音最相似的语音啦。至此,就完成声纹的识别过程啦。
不过,相信大家看了前面所讲到的语音波形图以及频谱图会非常疑惑,它们都向我们展示了什么信息呢?下面我们一一道来,在图2中我们可以看到语音的波形图,图中横坐标表示时间,纵坐标表示振幅,当振幅越大时,说明我们发出的声音越响亮,并且我们可以看到有的时刻波形密集,有的时刻波形稀疏,这是因为在某个时刻单位时间内震动的次数比较多,声音频率较高,因此声音波形越密集说明声音发声频率越高;
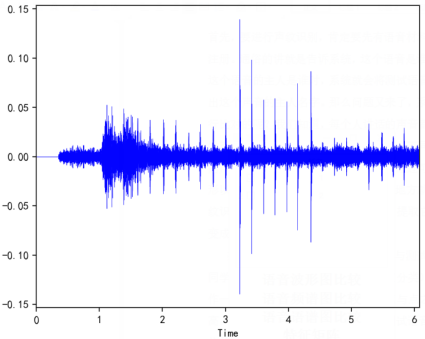
图2 语音波形图
接下来我们看看语音对应的频谱图,如图3所示,图中横坐标表示的是发声频率,纵坐标表示振幅,在某个频率上的柱形越长,表示在这个频率上声音越响亮。
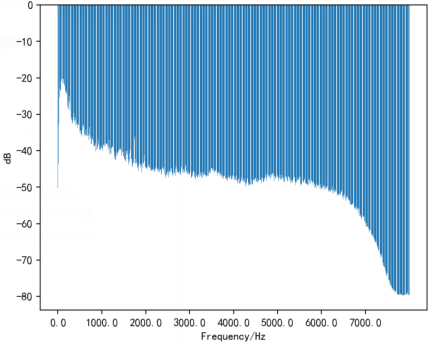
图3 语音频谱图
最后,虽然前面的两种图形已经看起来很直观了,但是我们仍然很难看出点什么来。接下来我们看一下声音的语谱图,如图4所示,横纵坐标分别表示时间和频率,在某个时刻某个频率上,他们的线条亮度各不相同,这表明声音在某个时刻某个频率上的声音振幅不同,也就是说当条纹越亮说明声音在这个频率上越响亮。它相比起频谱图,多了一个时间维度,能够更加直观的看出声音在不同时刻时频率与振幅等的关系。
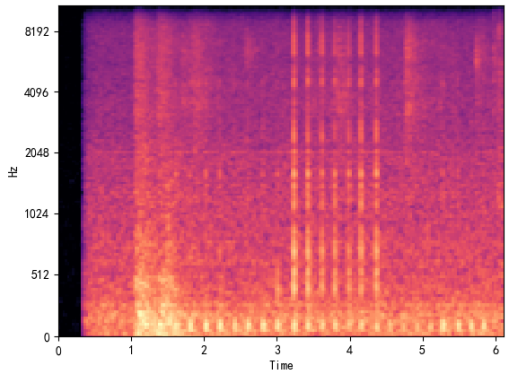
图4 语音语谱图
以上,便是声纹识别的一些相关知识,同学们学会了吗?
